
4차원으로 작동되고 있는 사람 유전체
유전체의 슈퍼-초고도 복잡성은 자연주의적 설명을 거부한다

사람 유전체(human genome)는 우주 내에서 알려진 것들 중에서 가장 복잡한 컴퓨터 운영 시스템이다. 그것은 단일-분자적 정밀성으로 작동되는 초고도-복잡성의 생화학을 제어하고 있다. 유전체는 수십만 개의 단백질들의 양방향 네트워크를 조절하고 있다. 그것은 하나님의 경이로운 창조적 능력을 보여주는 동시에, 신다윈주의 이론의 과학적 파산을 가리키는 훌륭한 증거가 되고 있다. 그 이유는 무엇인가? 왜냐하면, 생명체의 복잡성이 점점 더 커질수록, 무작위적인 자연적 과정에 의한 진화론은 점점 더 그 가능성이 낮아지기 때문이다. 초고도 복잡성의 기계는 계획도 없고 방향도 없는 어떤 사고들에 의해서 우연히 생겨날 수 없다. 어떤 사고는 고장을 유발하지, 더 성능 좋은 기계로 변화시키지 못한다. 그리고 슈퍼-초고도 복잡성의 기계는 더더욱 무작위적인 변경으로 생겨날 수 없다.
나는 유전체를 컴퓨터 운영시스템과 비교해보았을 때, 커다란 충격을 받았다. 이 둘을 비교해보았을 때, 이 세상의 어떤 컴퓨터도 유전체의 복잡성이나 효율성 측면에서 비교될 수 없었다. 그 비교도 가장 기초적 수준에서만 이루어질 수 있었다. 유전체는 극도로 복잡하고, 지속적으로 효율적으로 작동되고 있었다. 컴퓨터공학자들은 수많은 시간 동안 모든 기술력과 정보와 지식을 통해 프로그램들을 만들어낸 후에, 노트북이나 서버를 실행할 수 있는 운영시스템을 구축하게 된다. 그러나 그것도 결국 많은 장애들이 발생하고, 운영에 에러가 생긴다. 그러나 유전체에 들어있는 프로그램은 인체라 불리는 초고도 복잡성의 생물학적 기계를 완벽하게 운영 작동시키고 있다. 이 두 조직은 물론 근본적으로 다르다. 컴퓨터 과학자, 생물 물리학자, 생물 정보학자들로(정말로 똑똑한 사람들로) 구성된 한 연구팀은 하등한 대장균 박테리아의 유전체를 사람들이 만들어낸 리눅스(Linux) 운영 시스템과 비교해보았다(그림 1). 그리고 사람들이 만든 리눅스 운영 시스템이 훨씬 많은 상위 지침들을 가지고 있기 때문에, 훨씬 더 비효율적인 시스템이라는 것을 발견했다.1 박테리아 유전체는 적은 수의 상위레벨 지침들을 가지고, 적은 수의 중간레벨 지침들을 제어하고, 이들은 많은 수의 단백질 암호 유전자들을 제어한다. 리눅스는 그 반대이다. 리눅스는 훨씬 많은 상위레벨 및 중간레벨의 지침들을 가지고 있으면서도, 매우 비효율적으로 그것을 제어한다. 대장균은 적은 제어로 많은 일을 할 수 있는 것이다. 유전체학(genomics)의 연구는 미래에 컴퓨터 발전에 커다란 영향을 미칠 것으로 예측되고 있다.
또한, 사람이 만든 컴퓨터는 비교적 간단한 프로그램을 사용한다. 컴퓨터 프로그래머는 '코드 라인 수(lines of code)'에 대해서 이야기한다. 우리는 수학 시간에서 선(line)은 1차원이라는 것을 배웠다. 그래서 컴퓨터 프로그램은 기본적으로 1차원이다. 이에 비해 사람 유전체는 4차원으로 작동된다. 이것은 하나님의 창조적 능력이 얼마나 위대하신지를 보여주는 가장 강력한 증거 중 하나인 것이다.

1차원 : DNA 분자
사람 유전체는 약 1.8m 길이이다. 그것 전부가 미세한 세포핵 내에 들어가 있다. DNA를 사람의 머리카락 굵기로 가정한다면, DNA의 길이는 50km 이상이 될 것이며, 대략 골프공 크기 안에 들어가 있는 것이 될 것이다. 이것 하나만으로도 하나님은 경이로운 엔지니어시라는 것을 알 수 있다.
DNA에 암호로 들어있는 문자들의 순서를 나열해 놓는다면, 그것은 다음과 같이 보일 것이다 :
이것은 사람 Y 염색체(human Y chromosome)의 처음 700개의 글자이다. 동일한 염기서열을 가지고 4글자를 4색의 화소(pixels)로 대체한다면, 그림 2에서 보이는 것과 같은 것을 얻게 된다.2 이것은 매우 인상적이지 않은가?
유전체의 1차원은 단순히 글자들의 순서이다. 그 글자들은 유전자들에 적혀있는 것이고, 그 유전자들은 세포가 해야 할 일을 말해주고 있다. 이것도 복잡하지만, 상황은 더욱 복잡해진다.
2차원 : 상호작용하는 네트워크
유전체의 2차원은 DNA의 한 부분이 또 다른 부분과 상호작용하는 방법과 관련되어 있다. 우리가 이미 보았듯이, 1차원은 쉽게 그릴 수 있다. 그러나 2차원을 그리려면, 먼저 DNA의 선형 문자열의 다른 부분들을 연결하는 많은 화살표들을 그릴 필요가 있다. 그러나 유전체의 전체 상호작용 네트워크를 그린다는 것은 불가능하다. 그래서 한 작은 예만을 살펴보고자 한다. 마이크로 RNA(microRNA, miRNA)는 유전자 기능의 조절에 관여하는 매우 작은(약 22개 뉴클레오티드) 분자이다. 그림 3은 동맥경화증(atherosclerosis)에 대응하여 상향 조절되고 있는, 13개의 유전자들에서 작동되고 있는 miRNA 조절 네트워크의 한 부분을 보여주고 있다. 이들 유전자들은 262개 miRNAs에 의해 표적이 되고, 372개의 '조절 관계(regulatory relationships)'를 맺고 있다. 그림 3에 포함되지 않은 33개의 다른 유전자들이 있고, 그들은 295개의 miRNAs에 의해서 신체가 이러한 상황에 처할 때 하향 조절되고 있다. 기억해야만 하는 것은, 이것은 유전체의 2차원에 대한 극히 작은 부분에 불과하다는 것이다!

유전체의 2차원은 특이성 인자(specificity factors), 증강인자(enhancers,) 억제인자(repressors), 활성인자(activators), 전사인자(transcription factors) 같은 것들과 관련되어 있다. 이들은 DNA에 암호화되어 있는 단백질들이다. 그러나 그들은 만들어진 후에 유전체의 다른 부분으로 이동하고, 어떤 것의 스위치를 켜거나 끈다. 그러나 이 차원에서 일어나는 추가적인 것들이 있다. 단백질의 제조 공정 중에, 한 유전자는 ‘전사(transcription)’라 불리는 과정 동안에 세포에 의해서 '읽혀진다'. 여기에서, DNA는 RNA라 불리는 분자에 복사된다. 그리고 RNA는 한 단백질로 번역된다. 우리는 이 과정에 대한 훌륭한 애니메이션을 가지고 있다.(Multimedia site.) 그러나 전사후 조절(post-transcriptional regulation)이라 불리는 과정에서, RNA가 유전체의 또 다른 부위에 코딩되어 있는 다른 인자(miRNA 같은)에 의해서 활성화되기도 하고, 불활성화 되기도 한다.
수백만 달러의 연구자금이 들어갔던 엔코드 프로젝트(ENCODE project)는 아직 완전히 이해하지는 못하고 있었던, 유전체에 관한 어떤 것들을 밝혀냈다. 가장 큰 미스터리 중 하나는 약 22,000개의 유전자들이 300,000개 이상의 서로 다른 단백질들을 어떻게 생산하는지 그 방법에 관한 것이다. 그 답은 세포가 ‘선택적 스플라이싱(alternate splicing)’이라 불리는 한 과정을 통해서 진행한다는 것이다. 그 과정에서 유전자는 잘려지고, 조각나서, 다른 부분들이, 다른 시간에, 다른 세포들에 의해서 사용되어서, 다른 환경 하에서, 많은 다른 단백질들이 만들어지는 것이다. 이 믿을 수 없도록 극도로 복잡한 과정도 유전체의 2차원에서 단지 작은 한 부분에 불과한 것이다.
3차원 : DNA의 입체 구조
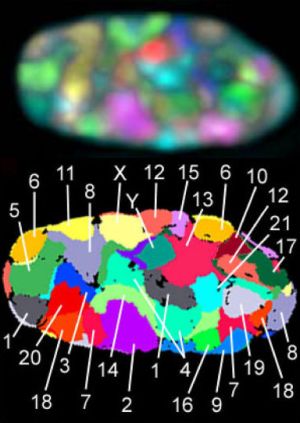
유전체의 3차원은 DNA 분자의 모양이 다른 유전자들의 발현과 조절에 어떻게 영향을 미치는지와 관련되어 있다. 우리는 감겨진 DNA 사슬 깊이 묻혀있는 DNA 부분이 쉽게 활성화될 수 없다는 것을 알고 있다.4 그래서 자주 사용되는 유전자들은 일반적으로 쉽게 접근할 수 있는 위치에 있다. 따라서 하나님이 1차원적 DNA 가닥에 유전정보를 써넣으실 때에, DNA가 3차원 모양으로 접혀졌을 때에 서로 정확한 위치들에 위치하도록, 의도적으로 어떤 순서를 가지고 그것들을 써넣으셨어야만 했다.
인간 게놈 프로젝트(Human Genome Project)로 밝혀진 가장 큰 사실중 하나는, 함께 사용되는 유전자들이 유전체 내에서 반드시 서로 가까이에 위치하지는 않는다는 것이었다. 진화론자들은 ”그것은 그냥 쓰레기(junk)이다”, 또는 ”유전체는 수백만 년의 시간 동안에 일어난 유전적 사고(genetic accidents)의 축적에 불과하다”와 같은 주장들을 했었다. 그러나 이러한 주장은 오래 가지 못했다. 왜냐하면, 과학자들이 유전체가 핵 안에서 어떻게 조직화되어 있는지를 살펴보기 시작했을 때5, 각 염색체는 핵 안에서 지정된 특별한 위치를 가지고 있을 뿐만 아니라, 함께 사용되는 유전자들은, 심지어 다른 염색체에서 발견되는 유전자들이라도 일반적으로 3차원적 공간에서 서로 서로 인접하여 발견된다는 것을 알게 되었다.
4차원 : 처음의 3차원이 변경됨
유전체의 4차원은 시간(time)이 흐르면서 처음의 3차원이 변경되는 것과 관련되어 있다. 그렇다. 도저히 믿을 수 없어 보이지만, 그것이 사실이다. 모양(3차원), 상호 네트워크(2차원), 글자 순서(1차원), 모든 것들이 변경된다. 이것은 지금까지 유례가 없는 것으로, 인간이 만든 가장 최첨단 컴퓨터도 따라올 수 없는 것이다.
4차원은 여러 가지 방법으로 설명될 수 있다. 다른 간세포(liver cells)들은 다른 염색체 수를 가지고 있다는 것이 알려져 있다.6 이것은 간은 대사 및 해독에 관여하는 어떤 유전자의 복사본을 많이 필요로 한다는 사실에 기인한다. 간은 이들 유전자들의 많은 복사본들로 유전체를 채우는 대신에, 자신의 사용을 위한 복사본들을 만든다. 또한 다른 뇌 세포(brain cells)들은 다양한 트랜스포존(transposons)을 다른 수로, 그리고 다른 위치에 갖고 있다.7 진화론자들은 이들 점핑유전자(jumping genes)들을 고대 바이러스 감염으로부터 남겨진 유물로 생각했었다. 문제는 그것들이 사람 뇌의 발달에 있어서 필수적이라는 것이다. 무슨 의미인지 알겠는가? 유전체는 다이내믹하게 자신을 재프로그램 시킨다. 이것은 컴퓨터 과학자들이 오랫동안 해결하려고 애써왔던 것이다. 당신은 통제를 벗어나지 않으면서 자가-변경되는 암호를 만들 수 있겠는가? 또한 트랜스포존은 마우스의 배아 발달을 조절하는 데에 중요하다는 것이 밝혀졌다.8 그러한 놀라운 부분을 진화론자들은 오랫동안 '정크 DNA(쓰레기 DNA)'라 불러왔던 것이다!
결론
유전체는 극도로 복잡한 생물학적 컴퓨터(biological computer)에 내장되어 있는, 오류를 자체 수정하며, 스스로 암호를 변경하는, 다중 차원의 운영시스템이다. 거기에는 여러 중첩된(이중) DNA 암호, RNA 암호, 구조 암호들이 들어 있다. 거기에는 DNA 유전자들 및 RNA 유전자들이 들어 있다. 유전체는 그것의 구축 동안에 생물공학적 원리들을 사용하셨던, 고도의 지적 존재에 의해서, 많은 량의 여분(redundancy)들이 있도록 의도적으로 설계되었다. 그러한 여분에도 불구하고, 22,000개 정도의 단백질 암호 유전자들이 상호 협력하여, 수십만 개의 독특한 단백질들을 한 치의 오차도 없이 만들어내도록, 경이로운 수준으로 치밀하게 압축되어 있는 것이다.
나는 진화론자들에게 도전을 하나 하겠다. 유전체의 기원을 설명해보라. 찰스 다윈(Charles Darwin)은 ‘종의 기원’에서 썼다 :
”만약 다수의, 연속적인, 약간의 변경들에 의해서 형성될 수 없을 것 같은, 어떤 복잡한 기관의 존재가 입증된다면, 나의 이론은 완전히 무너질 것이다.”
나는 이 인용문이 (창조/진화 논쟁에서) 남용되고 있다는 것을 알고 있다. 그러나 잠시라도 이것에 대해서 생각해보라. 간단한 생명체는 다윈의 관점으로 설명하기에 쉬웠다. 그러나 더 복잡한 생명체에 대해서는 그 문제는 더욱 어려운 문제가 되고 있다. 유전체는 앞에서 살펴본 것처럼, 극도로 초고도로 복잡하다. 이것은 진화론자들을 매우 불편하게 만들고 있는 것이다.
유전체는 알려진 자연적 과정을 통해서는 절대로 생겨날 수 없다고 나는 생각한다. 이 도전에 응전하기를 원하는 진화론자는 정보 변경의 원인, 필요한 돌연변이의 양, 필요한 선택적 힘… 등이 모두 적절한 시간에 작동되도록 하는 것 등을 포함하여, 적절한 시나리오를 우리에게 보내 달라. 진화론자들은 수십억 년이 걸린다하더라도, 무작위적인 자연적 과정은 그들이 필요로 하는 것을 만들 수 없다는 것을 발견하게 될 것이다. (참고 : DVD ‘The High Tech Cell’.)
참고 문헌및 메모
- Yan, K.-K., et al., Comparing genomes to computer operating systems in terms of the topology and evolution of their regulatory control networks. PNAS 107(20):9186–9191, 2010. 텍스트로돌아 가기.
- Seaman, J., and Sanford, J., Skittle: a 2-dimensional genome visualization tool, BMC Bioinformatics 10:452, 2009. 텍스트로돌아 가기.
- Lin, M., Zhao, W., and Weng, J., Dissecting the mechanism of carotid atherosclerosis from the perspective of regulation, International Journal of Molecular Medicine 34:1458–1466, 2014. 텍스트로돌아 가기.
- van Berkum, N.L., Hi-C: a method to study the three-dimensional architecture of genomes, Journal of Visualized Experiments 6(39):1869, 2010. 텍스트로돌아 가기.
- Bolzer, A., et al., Three-dimensional maps of all chromosomes in human male fibroblast nuclei and prometaphase rosettes, PLoS Biol 3(5):e157, 2005. 텍스트로돌아 가기.
- Duncan, A.W., et al., The ploidy conveyor of mature hepatocytes as a source of genetic variation, Nature 467:707–710, 2010. 텍스트로돌아 가기.
- Baillie, J.K., et al., Somatic retrotransposition alters the genetic landscape of the human brain, Nature 479:534–537, 2011. 텍스트로돌아 가기.
- Tomkins, J., Transposable Elements Key in Embryo Development; icr.org/article/6928, July 25, 2012. 텍스트로돌아 가기.



Readers’ comments
Comments are automatically closed 14 days after publication.