

Journal of Creation 19(2):29–35, August 2005
Browse our latest digital issue Subscribe
Inheritance of biological information—part I: the nature of inheritance and of information
Creationists need to rethink their understanding of inheritance. The current secular view is based on the inadequate Mendelian (genetic) paradigm and the inadequate statistical theory of information. The new understanding needs to be based on biblical creation and Werner Gitt’s multidimensional theory of information. The key element in the multidimensional theory is apobetics (purpose, especially the intention of the Creator) and this explains the failure of Darwinists to come to grips with the reality of biological information, because they reject the idea of purpose. Two different purposes can be identified in the biblical view of biology—stasis of created kinds and variety within kinds. We therefore need to look for two corresponding types of informational structures—one to explain stasis and one to explain variation. The cell may be the basic unit of inheritance that provides stasis, for its extra-nuclear contents pass unchanged from parent to daughter generation. Coded information on the chromosomes is also strongly conserved, but in addition it provides controlled variation within the created kind. The new science of semiotics may provide some useful tools for implementing the multi-dimensional approach to biological information.
The nature of inheritance
The current view of inheritance taught in our schools and colleges is Mendelian. Darwin imagined inheritance to occur by a blending of the characters of each parent, but Mendel showed that inheritance was particulate—it was carried by discrete particles in discrete states. These particles became known as genes, and genes were eventually found to be coded segments on the DNA molecules that make up chromosomes in the nucleus of cells. Darwinists today view all of inheritance as genetic, and because genes can change more or less indefinitely, they identify this as the obvious means to explain how everything has evolved from something else during the supposed millions of years of life on Earth.
But Mendel’s work only explained the things that changed during inheritance, not the things that remained the same. For example, he used varieties of pea plants that had round or wrinkled, green or yellow seeds. He simply took for granted, and thus overlooked, the fact that the peas produced peas. Darwinists today still remain blind to this fact and insist that peas will eventually produce something other than peas, given enough time. There is certainly enormous variability in all forms of life, yet all our experiments in plant and animal breeding still show the same result—peas produce peas, dogs produce dogs and humans produce humans. This result is not consistent with Darwinian expectations, but it is consistent with Genesis chapter 1, where God created organisms to reproduce ‘after their kind’.
Unfortunately, creationists today still tend to do their reasoning on the subject of inheritance in Mendelian terms. It is time that we developed a biblical theory of inheritance, and this article (in three parts) is an attempt to outline some principles required for such a theory. Here, in Part I, the nature of inheritance and of information will be considered, emphasising the 5-dimensional Gitt theory of information. In Part II, the ‘information challenge’ (where did the new information come from in ‘goo to you’ evolution?) will be reformulated in terms of the Gitt theory of information. And in Part III the biological mechanisms for control of information transfer and change will be examined in the light of biblical principles.
Static and variable inheritance structures
If inheritance was totally Mendelian, this would indeed favour the Darwinian model because, in principle at least, any and every part of a chromosome can be chopped and changed, and therefore variation should be unlimited. The ‘in principle’ rider is important because both internal and external constraints operate in practice. One external constraint, for example, is the survival of the organism, which requires practical limitations on the amount of change that can occur in any one generation. One internal constraint is that choices made at any particular stage in a selection process will shut off the deleted options for later stages in that lineage. Furthermore, the two sexes need to be genetically compatible for reproduction in order to pass on any change to the next generation.
But this argument leads to a paradox—chromosomes are potentially infinitely variable, while organisms are not infinitely variable. Is this just a matter of practical constraint, as Darwinists would argue, or is something more fundamental at work? Could it be that chromosomes are not the sole determinants of inheritance?
Cytoplasmic inheritance1 is now well documented. Organelles such as mitochondria, chloroplasts and the centriole all have DNA of their own that is passed on directly to the daughter generation in the cytoplasm of the mother’s egg cell, independently of chromosomal DNA. But this kind of inheritance is still particulate, coded and Mendelian. There is another kind of inheritance that is quite different—structural inheritance.
Living cells are extraordinarily complex in their structural and functional organization, as modern textbooks on cell biology testify.2 However, the more we study cells, the more we discover of their complexity. There seems to be, as yet, no end to their astonishingly intricate designs. Not only are they intricate and complex, they are amazingly fast and accurate in what they do. For example, the enzyme carbonic anhydrase can break down a molecule of carbonic acid in under 2 millionths of a second. Chemical reactions that go so fast need to be precisely controlled and integrated with other cell reactions, otherwise they will just as quickly go wrong and wreak havoc in the cell. And fatal diseases such as progeria and Tay Sachs disease can be produced by no more than one single mistake in the structure of just one single kind of molecule. Not every molecule is so intolerant of error, but the fact that some are means that not only can the cell avoid mistakes, but it can also normally correct them when they do occur to the supreme standard of 100% accuracy.
Such incredibly fast and accurate biochemistry at a submicroscopic level requires a wondrous array of minute transport, communication and control systems, otherwise chemical chaos would produce a plethora of unwanted (and fatal) cross-reactions. All of this structure is contained in the mother’s egg cell and is passed on in toto to the daughter cells. As a result, the fast and accurate biochemistry of the mother’s cell continues, seamlessly, to occur in the daughter cells without any interference from mutations or recombinations that might have occurred in the chromosomes.
If mutations or recombinations have occurred in the chromosomes in such a way as to modify the behaviour of the daughter organism relative to its ancestor, then such effects will come into play during the subsequent development of the offspring as nuclear information is used by the cell to guide the development and behaviour of the new organism.
Most of this structural inheritance has been overlooked by biologists. Until recently it was thought that cellular components moved passively from parent to daughter cells during cell division, carried along by the cell-division mechanism that duplicated the chromosomes and pulled them apart into the daughter cells. However, in 1999, Yaffe3 found that there was a complex of cellular machinery associated with the cytoskeleton that coordinates the distribution and movement of mitochondria throughout the cell. Recent developments in microscopy have allowed these structural components and their movements to be viewed in live cells.4 If mitochondria are catered for in this way, then obviously other cellular components are equally well catered for when it comes to cell division. Organelles such as mitochondria, peroxisomes, etc. then divide and proliferate in the daughter cell, once again independently of the replication that goes on in the nucleus and in the whole cell.
Mutations can occur in mitochondrial DNA, and this has been used to trace ancestral lineages in humans and other species, on the assumption that no recombination occurs in mtDNA. However, the recent discovery that recombination also occurs in mitochondria casts these types of studies into doubt.5 Such studies show that inheritance goes beyond the nuclear chromosomes, but it still ignores the microstructure of the cell that is so essential for all of these processes to occur.
Cellular inheritance
Genes can no longer be seen as the cause of biological inheritance because we now know that control over their expression (i.e. their being switched on and off when needed or not needed, respectively, and the timing of these events) comes from epigenetic mechanisms operating in the cell.6 This suggests that the DNA simply provides a ‘library’ of information and the use of that information is controlled not by the genes themselves but by the cell.
If the cell, and not the genes, control inheritance, then certain observations that puzzle Darwinists become explicable. For example, Australian rock hopper wallabies display an incredible array of chromosomal aberrations, yet all within a group of species that are so similar to one another that most people cannot tell them apart.7 The chromosomes have been grossly scrambled, yet the cell is still able to extract the information it needs for survival. If the genes had been in control during such a scrambling process, Darwinists would expect it to take about a hundred million years, but the evidence suggests quite recent divergence of these species.
A similar pattern of cell stability in the face of genome change is constantly at work in bacteria. It has been found that new gene sequences are continually being brought into bacterial cells and spliced into the bacterial genome.8 The bacterial genome does not keep getting bigger, however, because it also has a complementary method of getting rid of unwanted or useless sequences. The result is that the bacterium is continually ‘sampling’ its genetic environment, looking for new gene sequences that might be useful in the ever-changing world around it. Throughout all this change, the bacterium maintains its integrity as a bacterium. For example, a study of the bacterium Escherichia coli over 10,000 generations found that at the end, ‘almost every individual had a different genetic fingerprint’, yet they were still Escherichia coli.9 Only if the cell is in control can we explain these observations.
Another kind of evidence comes from the architecture of cells. When cell membranes were transplanted by microsurgery in ciliates, for example, the transplanted membrane pattern was inherited even though the DNA had not changed.10 This provides direct evidence for inheritance of cell architecture from cell architecture.
An illustration of how cell architecture and DNA interact is provided by an organelle called a ‘peroxisome’, which detoxifies cells by breaking down hydrogen peroxide. Peroxisomes self-replicate by binary fission and, like all other organelles, are passed directly from mother to daughter in the cytosol. Certain chromosomal mutations will suppress peroxisome development and it was originally thought that such mutant cells therefore lacked peroxisomes altogether. Further study, however, showed that a structural remnant of the peroxisome continued to be present, and was inherited, and it could be resurrected in subsequent generations by reversal of the chromosomal mutation.11 Thus, it seems that the cell passes on structural components upon which the genes act in a cooperative way to reproduce the architecture of the mature daughter cell.
So here we have an obvious source for the fixed information that maintains the integrity of the created kinds. When reproduction occurs, it is not just chromosomes that are passed on to the offspring, but whole cells—complete with cell walls, cytoplasm, organelles and the elaborate and extensive transport and communication and control networks that connect cells inside and out. These things are passed on independently of the genetic shuffling that occurs on the chromosomes. Thus, it is biologically possible (and perhaps blindingly obvious) to identify the cell as the unit of inheritance, not the chromosomes. Since cells appear to pass unchanged from parent to daughter generations, this could explain why organisms reproduce ‘after their own kind’ and are not infinitely variable as Darwinists assume.
The nature of information
Inheritance occurs by the transmission of information from parent to daughter generation. Because genetic information (i.e. that which is coded on the DNA molecule) is superficially easy to understand, it has dominated scientific thinking on inheritance. Yet the concept of information itself is quite complex and this complexity has limited creationists’ ability to break away from the Mendelian mould.
Information theory only began as a discipline in 1948 with the publication of Claude Shannon’s classic paper, entitled A Mathematical Theory of Communication.12 He was working on electronic communication (radio, television, telephone) and needed to create a high signal-to-noise ratio that would ensure accurate transmission of messages. While he acknowledged that messages ‘frequently have meaning’, he went on to say that ‘These semantic aspects of communication are irrelevant to the engineering problem.’ He quantified information statistically, in terms of all possible ways of arranging the symbols that carried the messages.
Another approach to quantifying information is called algorithmic information theory. In this view, the information content of any object is defined as the shortest binary computer program that would adequately describe it. In one of the pioneering papers in this field, Gregory Chaitin claimed that his method was theoretically capable of describing biological systems, but he also acknowledged its practical limitations: ‘We cannot carry out these tasks [i.e. biological descriptions] by computer because they are as yet too complex for us—the programs would be too long.’13 Creationist biophysicist Lee Spetner used an algorithmic approach to enzyme specificity to determine whether genetic mutations could produce new information.14 While he concluded that mutations could not do so, others have claimed that a more rigorous application of his method shows the opposite result, that mutations can produce new information.15 This illustrates the potential complexity of information arguments.
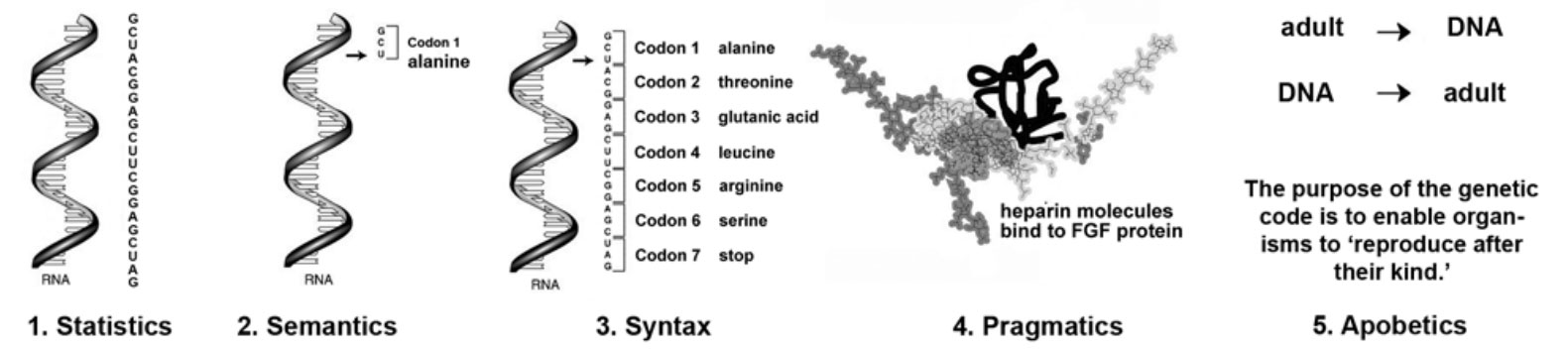
Intelligent Design theorist William Dembski has identified his work on complex specified information as constituting a theory of information different to the former two.16 He defines information in its most general sense as ‘the actualization of one possibility to the exclusion of others’ and claims that ‘this definition encompasses both syntactic and semantic information’. He thus treats information as a multidimensional entity, not just a one-dimensional entity as Shannon and Chaitin treated it. His first dimension is statistical—he defines complex as being ‘an improbable arrangement of elements’. He then includes dimensions of syntax (ordering rules) and semantics (symbolic associations or meanings) when he defines specified as ‘conforming to a predetermined pattern’. But Dembski’s work stops there. Information specialist Werner Gitt goes on to show that information actually has five dimensions.17
The Gitt theory of information
In his book In the Beginning was Information, Gitt did not apply his analysis to biology in any detail, so I will here explain it by applying it to biological information and to information as expressed in the English language. The genetic code consists of four bases (the genetic alphabet) taken three at a time (the genetic words). The four bases are guanine (G), adenine (A), cytosine (C) and uracil (U).18 Four bases taken three at a time yield 64 possible three-letter genetic words (there are no one-, two-or four-letter genetic words). There are twenty amino acids and each three-letter ‘codon’ (word) represents one amino acid or a ‘stop’ or ‘start’ sign. Several different codons can represent the same amino acid (since 64 is greater than 20) but each codon represents only one amino acid. For example, GCA, GCC, GCG and GCU all represent alanine, and UAA, UAG and UGA all represent the ‘stop’ sign, but AUG alone represents methionine.
Let’s now consider some three-letter English words for comparison. Cat, mat, bat, hat, fly and sky are all three-letter English words that carry approximately similar Shannon-type statistical information content. Yet we all know that these words carry much more information than just the statistical properties of their letter frequencies. The most obvious extra dimension is their semantic content. ‘Cat’ represents a furry, four-legged mammal, ‘bat’ represents a flying mammal, ‘hat’ is a shading device placed on human heads, etc. In an exactly parallel fashion, the genetic codons UUU and CGA have semantic content as well—the former represents the amino acid phenylalanine, and the latter represents arginine.
The next dimension of information is syntax—the place value or ordering rules of the words. The English sentence ‘A bat can fly in the sky’ is meaningful, but ‘The sky can fly in a bat’ is not. Likewise, syntax is a component of the meaning of genetic words. For example, the correct sequence of amino acids in the enzyme hexosaminidase A can produce a healthy human child, but a single error in that sequence can produce a child with the fatal Tay Sachs disease.
A fourth dimension of information is pragmatics—the practical functionality of words. For example, ‘a bat can fly in the sky’ is a statement about the capability of bats. This statement could have a practical application in a children’s book, for example, to teach children about the world around them. Information always has some practical application; it does not just float around in the air waiting for somewhere to settle and become meaningful. In an exactly parallel way, the amino acid sequence in hexosaminidase A has a practical function in preventing the abnormal build-up of fatty substances in human brain cells.
The fifth dimension of information is apobetics (teleology or teleonomy)—the overall purpose for which a particular word sequence is produced. In the case of the children’s book cited above, the overall purpose is that parents want their children to learn about the world around them so that they will grow up to be good citizens (and perhaps look after their parents in their old age). In the case of the amino acid sequence in hexosaminidase A, the overall purpose is to produce a viable human being capable of worshipping God and having offspring. Failure to achieve this purpose will lead to clogging of brain cells with fatty ganglioside molecules, consequent degeneration of the brain, and death in infancy.
We can now see that Shannon’s statistical approach to information ignores all four of these ‘extra’ dimensions of information. The reason is quite straightforward—Shannon was originally interested in quantifying the concept of information, and there is no easy way to quantify semantics, syntax, pragmatics or apobetics. They are no less real, however, and this is the challenge that creationists face. We cannot simply say, as Shannon did, that ‘[the] semantic aspects of communication are irrelevant to the engineering problem’. They are certainly not irrelevant to the biological problem.
The higher dimensions of biological information
Fifty years of molecular biology have produced enormous advances in knowledge, but you won’t find any discussion about these ‘extra’ dimensions of biological information in any standard textbook on biology. No doubt, progress could continue without ever addressing the issue. But no biologically realistic worldview can develop without addressing this question, because it is here that we find ‘meaning’, ‘order’, ‘practical application’ and ‘purpose’. To incorporate these extra dimensions into our understanding of biology, we first need to know more about them.
Semantics
The essence of semantics is symbolism. The English word ‘cat’ has no statistical, alphabetical or biological relationship with the furry mammal that it refers to. The relationship is purely arbitrary. The equivalent (and different) words in Russian, Chinese and Arabic are entirely as satisfactory for the intended purpose as the English word. English speakers at some time in the past chose to use the word ‘cat’ and we continue to use it by convention in order to maintain effective communication. In every language the relationship between the furry mammal and the word that represents it is purely symbolic. Symbolism is an activity of the mind that does not have any physico-chemical basis in biology. A multilingual human can speak about a cat in several different languages, yet say exactly the same thing using different symbols. The mind—and nothing else—makes the connection between the words and the objects that they symbolize.
In the genetic code, the relationship between UUU and phenylalanine is likewise symbolic. There is no physicochemical or biological reason why UUU should not represent glycine, lysine or serine rather than phenylalanine. At some point, ‘someone’ made a choice and decided that UUU would represent phenylalanine. And in order to maintain effective communication between parent and daughter cells, the convention has been strictly maintained ever since. While some variations from the standard code do exist in some microbes and mitochondria, the symbolism is strictly maintained within each such lineage. Indeed, the slight variations in the code highlight the purely arbitrary nature of the relationship between codon and amino acid—the symbols can be changed!
Since semantics is based on symbolism, and symbolism is a purely mental connection between object and symbol, this may explain why evolutionary biologists have ignored the matter of the ‘extra’ levels that exist in biological information. They do not want to admit any such anthropomorphisms (or worse) into their naturalistic biology.

Syntax
The essence of syntax is structure. As already mentioned, the English sentence ‘A bat can fly in the sky’ is meaningful, but ‘The sky can fly in a bat’ is not. Word order in English is crucial to meaning. Yet the rules of English syntax are arbitrary—the rules are different in other languages. In Greek, for example, word order can be changed without changing the meaning, but different word orders will give different emphases to that same meaning.
Syntax in the genetic code is like the English language where word order is crucial to meaning. One of the smallest biologically useful protein molecules is insulin. It contains 51 amino acids. Now there are 2051 = 1066 ways of arranging 51 amino acids into chains, but only a very small number of these are biologically useful. For example, beef insulin differs from human insulin in only two places, and pork insulin in only one place. Even fish insulin is close enough to human insulin to be effective in humans. Hexosaminidase A is about an average-sized molecule and it contains 529 amino acids. There are 20529 = 10688 different ways of arranging 529 amino acids into a protein chain, but just one single error in the sequence can be sufficient to produce the fatal Tay Sachs disease. Other proteins can be much larger—the muscle protein titin, for example, consists of 27,000 amino acids. The number of wrong ways in which the amino acids in these proteins could be assembled is approximately 2027,000 = 1035,127. So the fact that they are usually assembled in precisely the correct order, and only allow the most minute variations, testifies that cells are extremely sensitive to syntax in the genetic language.
Pragmatics
The essence of pragmatics is context. The English sentence ‘A bat can fly in the sky’ tells us something about the capabilities of the small, furry mammal (it can fly) and where it can exercise that capability (in the sky). But this sentence has no function on its own. It is entirely dependent upon the context of an English-speaking writer and/or reader to become functional. Its function is also likely to be just one component part of some larger work that describes batsin greater detail.
Just as an English sentence requires a context (writer and/or reader) to be functional, so the function of a protein molecule is entirely dependent upon the cell. Life does not exist outside of cells. Viruses are simpler than cells but they can only reproduce inside functional host cells. Some microbes can have acellular stages but they retain a full complement of cell contents and mechanisms and require a cell stage to complete their life cycle.
The biological function of a protein does not come just from its amino acid sequence, but from its three-dimensional shape. The precise amino acid sequence in a protein chain determines the ways in which it is able to fold into that three-dimensional state. The wrong amino acid in the wrong place may produce a 3-D structure that is out of shape and so fails to achieve its required function. Furthermore, other proteins, called chaperones, are necessary for the correct folding of many proteins; so the amino acid sequence only generates the correct shape in the context of a cell with chaperones. Moreover, the context within which each molecule in a cell exercises its function is extremely dynamic—the molecule must appear when and where it is needed and then disappear when and where it is not needed. If, for example, hexosaminidase A does not appear at the right time and place and/or does not function properly, then fatty ganglioside molecules build up in brain cells, causing the brain cells to degenerate and the child to die.
Apobetics
The essence of apobetics is inverse causality—present processes occur because of some future goal. All human languages have a purpose—communication between individuals. A vast range of other organisms (perhaps all organisms) also communicate in many and varied ways, and each has a purpose in doing so, but only humans use syntactic language. For example, white-tailed deer communicate alarm by flicking up their tails. The flash of the white tail has semantic content—it means danger is near. But it has no syntax capability like in the English language, where 26 letters can be combined in different ways to form hundreds of thousands of words that can be then arranged in an infinite number of ways to communicate unlimited different ideas and messages. In further contrast, apes can learn hundreds of symbols and can communicate quite a range of semantic content, and their communications also show pragmatic and apobetic content, but they have no syntax capability like humans.
The language of DNA also has purpose. The discipline of embryology would be incomprehensible without apobetics. For example, the large, bony plates on the back of the stegosaur are of no practical use to the embryo, yet the stegosaur embryo develops these plate structures. The reason it does so is for the benefit of the adult (it is currently supposed that the adult used them for temperature control). The end (the benefit to the adult) determines the means (the development in the embryo). Non-biological causality usually proceeds the other way around—the cause precedes the effect. But in biology, the effect (embryonic development) precedes the cause (the needs of the adult organism). This inverse causality is the essence of apobetics. In Part II of this paper, when we use the Gitt theory to analyze information change, we will find that apobetics is the major determinant of information change.
Applying the Gitt theory of biology
It is genetic engineers, not Darwinists, who are using biological information to its fullest extent. They are the ones who look for semantic content (i.e. what protein a particular codon sequence refers to), whereas Darwinian phylogeneticists simply use the overall similarity between DNA sequences (irrespective of semantic content) to construct phylogenetic trees. Genetic engineers are the ones who are working out the syntax of genes (i.e. where they occur on the chromosomes and what their relationship is to adjacent and/or internal non-coding sequences). They are the ones discovering pragmatics (i.e. what the genes actually do). And they are the ones who are applying their knowledge to novel purposes (apobetics) such as gene therapy and improved crop production. Such an analysis of biological information is lethal to Darwinism because what Darwinists dismiss as ‘the appearance of design’ becomes ‘intelligent design’ in the hands of the genetic engineers. Yet even the genetic engineers, it seems, are mostly oblivious to the implications for intelligent design that their work entails.
But the fact that genetic engineers are forging ahead without producing any new biological theory of information illustrates how difficult it is to grasp and implement these concepts. However, Italian biologist Marcello Barbieri believes he has found a way of moving on from the ‘statistics only’ view of information through what he calls the semantic theory of biology.19 He argues that we cannot make progress in this area until we find a mechanical model from which we can develop a mathematical model, which we can then use to integrate and organize the information and make experimentally verifiable predictions.
By way of explanation, Barbieri points out the mechanical and mathematical models underlying Darwin’s theory. Darwin developed his theory of natural selection by bringing together the experimental results of plant and animal breeding (i.e. organisms reproduce with slight variations that are subsequently inherited) with the population model of Thomas Malthus (i.e. populations grow exponentially, forcing a competition for resources). Barbieri then uses a computer as a mechanical model of the Mendelian (genetic) view of life. A computer with its hardware and software is a good analogy, taking the cell as the hardware with the genome as the software. But computers do not ceaselessly repair and reproduce themselves, as cells do, so this clearly exposes the inadequacy of the genetic view of life. Something more is needed.
Barbieri has brought together the problem of embryonic development (i.e. how can one cell differentiate into something as complex as a tree or a human being?) with an ingenious mathematical solution that he developed to the problem of reproducing computed tomography images from a less-than-complete set of data. Analytical solutions (that is, straightforward exact solutions) to the computed tomography problem exist, but only for impractically small data sets. For real life (large) data sets, an iterative method is required. But working iteratively with a complete set of tomographs is deadly slow and uses huge amounts of computer memory. Barbieri discovered that by adding a memory matrix to his results matrix (i.e. not only keeping track of the current best picture, but also remembering highlights from the past) he could rapidly converge onto the required image with as little as 10% of the full complement of tomographs.
Applying this principle to embryological development, Barbieri argues that growth from zygote to adult is a process of reconstructing the adult organism from incomplete starting information (i.e. only that which is in the zygote). His model predicts the existence of biological memory matrices that assist the process, and he is able to name at least some of them. For example, when embryonic cells differentiate they remain differentiated for life. A memory of differentiation must therefore be lodged somewhere within each cell. Similarly, the location of each cell within the body plan of the organism is remembered for life (and can be considerably rearranged during insect metamorphosis), so a memory of body plan must exist somewhere. He cites other examples as well.
Now for a memory to be a functional part of an organism (or a computer) there must be a code that relates each item in the memory to its functional complement in the organism. As an example, the genetic code relates DNA codon sequences (i.e. the genetic memory) to functional amino acid sequences in proteins. In a similar way there must be a differentiation code that relates the information in the ‘differentiation memory’ to the repair mechanisms in the cell that ceaselessly maintain the cell in its differentiated state.
Barbieri admits that much work needs to be done to develop and test these ideas, but he certainly seems to have opened a door to new ways of looking at life. The three main points of his semantic theory are:
- The cell is fundamentally an epigenetic, rather than a genetic, system (i.e. cells and not genes control inheritance).
- While the genes provide a genetic memory for the cell, there are other memories (waiting to be discovered and described) that assist in many aspects of embryonic development.
- Each memory has its associated code—an arbitrary but irreducible and essential semiotic (see below) system—to enable the memory information to be implemented within the ceaseless self-maintenance of the cell.
Conclusion
The Gitt theory of information provides a whole new way of looking at biology. Purpose (apobetics) becomes the primary concern, rather than chance, as in Darwinism. Stasis of the created kinds requires the conservation of biological information, not the continual change that is required in Darwinism. Multi-dimensional information is also a very complex subject and requires a new way of thinking about life. Barbieri’s semantic theory of biology may provide a way ahead.
In Part II of this article, I shall reformulate the ‘information challenge’ (where did the new information in ‘goo to you’ evolution come from?) in terms of the Gitt theory. In Part III (to appear in a future issue of JoC), I shall look at experimental evidences for the way information is transferred and changed in biology.
A parallel can be drawn between information, as expressed in the English language (left), and biological information (above). The five dimensions in Werner Gitt’s theory of information (see previous image) can be applied to understand both the genetic code in DNA and the English language system.
References
- Sapp, J., Beyond the Gene: Cytoplasmic Inheritance and the Struggle for Authority in Genetics, Oxford University Press, New York, Ch. 7, 1987. Return to text.
- For example, Alberts, B. et al., Essential Cell Biology, 2nd ed., Garland Science, New York, 2004. Return to text.
- Yaffe, M.P., The machinery of mitochondrial inheritance and behavior, Science 283(5407):1493–1497, 1999; <www.sciencemag.org/cgi/content/abstract/283/5407/1493>. Return to text.
- Yaffe, M.P., Stuurman, N. and Vale, R.D., Mitochondrial positioning in fission yeast is driven by association with dynamic microtubules and mitotic spindle poles, Proc. Nat. Acad. Sci. USA 100(20):11424–11428, 2003; <www.pnas.org/cgi/content/abstract/100/20/11424>. Return to text.
- Piganeau, G., Gardner, M. and Eyre-Walker, A., A broad survey of recombination in animal mitochondria, Molecular Biology and Evolution 21(12):2319–2325, 2004; <mbe.oupjournals.org/cgi/content/abstract/21/12/2319>. Return to text.
- Egger, G., Liang, G., Aparicio, A. and Jones, P.A., Epigenetics in human disease and prospects for epigenetic therapy, Nature 429:457–463, 2004. Return to text.
- Williams, A.R., Jumping paradigms, Journal of Creation (formally TJ) 17(1):19–21, 2003. Return to text.
- Bergman, J., Did God make pathogenic viruses? Journal of Creation (formally TJ) 13(1):115–125, 1999. Return to text.
- Papadopoulos, D., Schneider, D., Meier-Eiss, J., Arber, W., Lenski, R.E. and Blot, M., Genomic evolution during a 10,000-generation experiment with bacteria, Evolution 96(7):3807–3812, 1999. Return to text.
- Meyer, S.C., The origin of biological information and the higher taxonomic categories, Proceedings of the Biological Society of Washington 17(2):213–239, 2004. Return to text.
- Purdue, P.E. and Lazarow, P.B., Peroxisome biogenesis, Annual Review of Cell and Developmental Biology 17:701–752, 2001. Return to text.
- Shannon, C.E., A mathematical theory of communication, The Bell System Technical Journal 27:379–423, 623–656, 1948; <home.mira.net/~reynella/debate/shannon.htm>. Return to text.
- Chaitin, G.J., Information-theoretic computational complexity, IEEE Transactions on Information Theory IT–20:10–15, 1974; <www.umcs.maine.edu/~chaitin/ieee74.html>. Return to text.
- Spetner, L.M., Not by Chance! Shattering the Modern Theory of Evolution, Judaica Press, New York, Ch. 5, 1998. Return to text.
- Musgrave, I., Spetner and Biological Information, <home.mira.net/~reynella/debate/spetner.htm#string length>, version 1.8, 2003. Return to text.
- Dembski, W.A., Intelligent Design as a Theory of Information, Access Research Network, William A. Dembski Files <www.arn.org/docs/dembski/wd_idtheory.htm>. Return to text.
- Gitt, W., In the Beginning was Information, Christliche Literatur-Verbreitung, Bielefeld, Germany, 1997. Return to text.
- This is the code on the messenger RNA, which is transcribed from the DNA and is used to control the sequence of amino acids to make proteins. Thymidine replaces uracil in the parent DNA code. Return to text.
- Barbieri, M., The Organic Codes: the birth of semantic biology, published online at: <www.biologiateorica.it/organiccodes/>. Return to text.

Readers’ comments
Comments are automatically closed 14 days after publication.