

Journal of Creation 16(3):111–115, December 2002
Browse our latest digital issue Subscribe
Our eye movements and their control: part 1
Summary
This is the first of two papers whose aim is to review briefly how our eyes move and how eye movements are controlled, as another example of awe-inspiring precision engineering by the Almighty. Evolution cannot begin to account for such coherent integrated complexity. This paper will consider the extraocular muscles and the mechanics of eye movements while the paper to follow will consider their cerebral control.
For most of us who are fortunate enough to enjoy normal binocular vision, we perhaps give little thought to the wonder of what happens to enable us to glance this way and that without conscious effort. We tend to take it for granted—until something goes wrong. Then we become acutely aware of characteristic symptoms such as double vision and the confusion of two images, or a feeling of disorientation. This paper aims to review briefly some aspects of how our eyes move and the implications regarding origins that arise from this.
The reader may find it helpful to refer to the glossary of terms appended at the end.
Double vision and squint
With our two eyes, two optical images of the world about us are formed simultaneously, one on the retina in each eye. These images are transduced and processed by the retinas and then transmitted to the brain via the optic nerves. How is it then that we do not see two images, i.e. do not have double vision? The answer to this question has to do with the way the visual pathway (retina to brain) is organised or ‘wired’. Each point of the retina in one eye must correspond with a point of the retina in the other eye so that the two optical images can be superimposed and fused in the brain to produce a single mental image. Thus it has been found that the data from the photoreceptors of corresponding points (one in each retina) converge on a group of neurons in the visual cortex of the brain, thereby giving rise to the single mental image.1,2 The two most important corresponding retinal points are the fovea in each eye through which passes the line of sight or visual axis. However, when the two visual axes fail to be directed toward the same object (the condition termed squint or strabismus) the retinal image in the squinting eye is displaced relative that in the non-squinting or fixing eye (Fig. 1). In other words, non-corresponding points of the two retinas are stimulated by the same image and diplopia is experienced by the subject. At the same time with squint, the data from corresponding points in the two retinas will be different and so cause visual confusion or rivalry (alternating inhibition of vision in one eye and then the other).
Furthermore, each point in one retina actually corresponds with a small area, rather than a point, in the other. This allows for a small degree of disparity between the two images, arising from the slightly different view each eye has of an object. The brain uses this disparity to generate depth or distance perception, termed stereopsis. Because of this a one-eyed person for certain activities is significantly handicapped, e.g. in ball games. Also for such a subject occupations demanding a high degree of stereopsis such as crane driving, piloting aircraft, microsurgery etc. are precluded.
Thus for the two optical images to be superimposed in the brain there needs to be constant accurate and coordinated orientation of the two visual axes towards the same object in space. This function is effected by the extraocular muscles, now to be considered, together with their control systems.
The mechanics of eye movements3,4
Each globe (eyeball) is housed in a deep bony socket, the orbit, which affords a measure of protection for the globe and a secure rigid origin (attachment) for each muscle moving it. The planes of the two outer walls are perpendicular to each other (Fig. 2) while the two inner walls are parallel. Thus the axes of the two orbits form an angle of 45°. Within the orbit the globe is surrounded by a fascial layer of fibroelastic connective tissue (Tenon’s capsule) whose inner surface is smooth and glistening which facilitates free unimpeded movement of the globe. By means of its attachments to the orbital periosteum (the fibrous membrane lining the orbital cavity) Tenon’s capsule suspends the globe. The muscles, nerves and vessels of the globe pass through this capsule and in the case of the muscles they each receive a sleeve by backward extensions from Tenon’s capsule. I will mention later more of what has been discovered about this capsule. Filling all spaces in the orbit unoccupied by these structures is a specialised fatty tissue which cushions the globe.
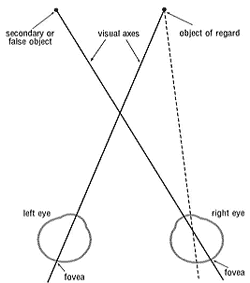
Figure 1. Corresponding points and squint. The two foveas are corresponding points. Because the right eye is deviated, the image of the object of regard falls on a non-corresponding point and so causes diplopia.
The direction of gaze of each globe at any given moment is determined by a delicate and extremely precise balance of rotational tractions exerted by 6 muscles. Even when seemingly at rest, these muscles are constantly active with a low level of tonic innervation. When looking steadily at an object this requires continuous fine movements of the eyes, so fine that they are only detectable with equipment which can magnify them.5 Without such fine movements, the retinal photoreceptors would adapt and cease to respond.6 Every muscular contraction has to be balanced by reciprocal relaxation of muscles opposing the action. This balance of muscular activity maintains the globe’s centre of rotation with its every movement in a constant position (within narrow limits) relative to the orbit.7 When studying deflections of the visual axis it has been found that the visual axis does pass through a point fixed, or nearly fixed, relative to the orbit.8 Indeed, if there were no balance of contraction with reciprocal relaxation, as occurs in certain disorders of ocular motility, the globe would not rotate about a fixed centre of rotation. Instead, depending on which muscles were contracting, it is either retracted into the orbit or protruded. Clearly such a malfunction (termed cocontraction) interferes with and impedes eye movements, causing misdirection of the visual axis with consequent degradation of vision.
The extraocular muscles (EOMs—Figures 3 and 4) are the group which rotate a globe by virtue of their respective attachments to its external surface. They comprise for each eye the four rectus muscles (medial, lateral, superior and inferior) and the two obliques (superior and inferior).9,10 The recti arise posteriorly at the apex of the orbit from a common origin, a fibrous ring around the exit of the optic nerve; they pass forward to their respective insertions on the globe anterior to the plane of the globe’s centre of rotation. The recti thus overall tend to pull the globe back into the orbit. This backward pull of the recti is balanced partly by the forward pull of the obliques and partly by the cushion of orbital fat.11
It is important to appreciate from the diagrams of this paper that the action of each muscle is a function of the orientation of the globe relative to the orbit. When our two eyes rotate to a new orientation (i.e. direction of gaze), the action of each of our twelve extraocular muscles changes. Moreover, during any rotation of the globe these changes of action come into play as a seamless highly coordinated continuous process.
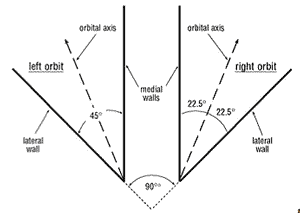
Figure 2. Diagram of the orbits and their axes.
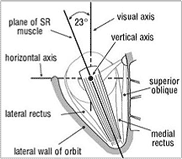
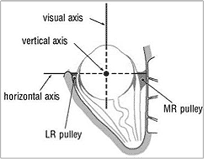
The actions of each muscle can be resolved mathematically into three components referable to three principal axes which pass through the centre of rotation and which are perpendicular to each other. The three axes (Fig. 3) are horizontal, vertical and anteroposterior (the visual axis or line of sight). The horizontal and vertical axes both lie in the equatorial plane (Listing’s) of the globe. The muscle actions are best understood by considering the insertion (attachment) of each muscle to the globe in relation to the globe’s centre of rotation.
The superior rectus (SR—Fig. 3) muscle passes forward in the orbit in alignment with (above and in the plane of) the orbital axis, as also does the inferior rectus below. Because it is inserted on the globe anterior to its equator and above, its primary action is elevation or supraduction (rotating the globe upwards). But this is its sole action only when the visual axis is also aligned with the axis of the orbit, i.e. abducted (turned out) about 23° from the primary position (the term used for the eye looking directly ahead). As the eye is adducted (turned in) from 23° of abduction, then increasingly the action of the SR changes from simple supraduction to a combination of adduction and intorsion (rolling about the visual axis). In adducting the eye the SR assists the medial rectus (MR) in the latter’s primary action of adduction. If the eye is abducted beyond 23° the action of the SR changes to become increasingly a combination of abduction (assisting the LR) and extorsion. All of these actions of the SR are normally balanced by corresponding but opposite actions of the inferior rectus.
As explained above, when the eye is adducted the vertical recti (superior and inferior) are less or not effective in elevating or depressing the eye. These become the functions of the oblique muscles which in adduction are very efficient, the superior oblique (SO—Fig. 4) for depression and the inferior oblique for elevation. The SO has its origin at the apex of the orbit above and medial to the origins of the SR and MR. The belly of the SO passes forward above and medial to the globe to near the entrance of the orbit. Here it becomes a rounded cord tendon and, uniquely among the EOMs, to turn sharply through a cartilagenous loop which acts as a pulley (the trochlea, Gk. for pulley), passing backwards, downwards and laterally. The tendon terminates by fanning out to be inserted on the upper posterolateral quadrant of the globe, i.e. behind its equator and centre of rotation. The SO tendon in passing back from the trochlea, forms an angle of about 54° with the medial wall of the orbit and with the visual axis in the primary position. Only when the eye is fully adducted to (54°) does the visual axis become aligned with the SO tendon and the SO then acts purely as a powerful depressor. As the eye is swung out so the SO becomes less and less a depressor until in full abduction it causes only abduction (assisting the LR) and intorsion. The SOs play a major role when we look down at a near object, e.g. when reading. In this act the SOs are the main depressors because the eyes (the visual axes) are converged, i.e. both are adducted.10
The inferior oblique (IO) runs a shorter course from its origin on the anteromedial part of the orbital floor; it passes back and laterally below to be inserted into the lower posterolateral quadrant of the globe’s surface and behind the equator. Similar to the SO, it forms an angle of about 51° with the medial wall of the orbit. The actions of the IO correspond with and balance those of the SO. Both oblique muscles are powerful torters of the globe in the primary position and in abduction. From the primary position direct elevation and depression is effected by muscles working as synergistic pairs: SR and IO for elevation and IR and SO for depression.
The horizontal recti (medial and lateral, MR and LR respectively) are like the reins of a horse. Although anatomical descriptions of the horizontal recti generally state their actions to be purely horizontal, in mechanical terms and in practice, these two muscles do acquire a vertical action when the globe is elevated or depressed.11 When the globe is rotated up they assist the elevators (SR and IO) and when rotated down the depressors (IR and SO). This principle is exploited in an operation designed to elevate the eye in some cases of elevator palsy: the MR and LR are detached and then reinserted at a higher level, above that of the centre of rotation and alongside the SR.12 Likewise, the horizontal recti can have a mild torsional action, depending on the direction of gaze. For example, when the globe is elevated the lateral rectus (LR) tends to rotate it about the visual axis (intorsion) but this is normally balanced and cancelled by the action of the MR (extorsion).
Tenon’s capsule
Recent studies using high-resolution magnetic resonance imaging (MRI) and cadaver dissections, have demonstrated a hitherto unknown functional importance of Tenon’s capsule and its muscle sleeves.13,14 This has led to a reappraisal and some modification of our understanding of the actions of the extraocular muscles outlined above. Previously, computerised tomography (CT) and MRI studies had shown the stability of the rectus muscle bellies relative to the orbit during eye movements with only the tendons moving because of their attachments to the globe. These observations were confirmed by fact that MRI after surgery in which muscle insertions were moved revealed no change in the position of the rectus muscle bellies. Such findings conflict with the conventional notion that the recti follow the shortest path from their origins to their insertions and have highlighted the presence and mechanical role of supporting orbital tissues, principally Tenon’s capsule.
 |
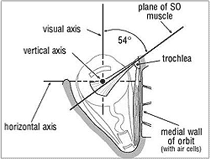 |
| Figure 3. Diagram of the left superior rectus (SR) muscle. | Figure 4. Diagram of the left superior oblique (SO) muscle (the superior rectus and levator muscles removed). |
 | |
| Figure 5. Diagram of the Tenon’s capsule pulleys for the horizontal rectus muscles. | |
Tenon’s capsule is thicker and tougher where the rectus muscles penetrate it about the plane of the globe’s equator when in the primary position, i.e. looking directly ahead. Each rectus muscle, as it passes through Tenon’s capsule, occupies a tunnel which is firmly tethered to the adjacent orbital periosteum (the fibrous membrane covering the bone), like the trochlea, and acts as a pulley (Fig. 5). Depending on the direction of gaze, these pulleys change the direction of pull of each rectus muscle and so become the functional origin for the muscle (Fig. 6). They reduce or eliminate the subsidiary actions of the recti that would otherwise occur in the absence of pulleys. They also maintain the spacing between neighbouring rectus muscles from their origins to their passage through Tenon’s capsule. Likewise, they restrict muscle side slippage of, for example, the horizontal (medial and lateral) recti during vertical movements. Nonetheless, Demer et al. acknowledge that there is some laxity in the pulleys of Tenon’s capsule which does allow subsidiary actions of the recti as described above to a degree.
A puzzle solved
To complicate matters still more, it was found by Donder in the middle of the 19th century that a form of torsion of the globe always occurs whenever it is rotated to any oblique position, e.g. simultaneously up and medially.15,16 This effect is predictable for any given oblique (tertiary) position. It indicates rotation of the globe about an axis intermediate between the vertical and horizontal in Listing’s plane and perpendicular to the direction of movement. This can easily be verified by staring directly ahead at an upright luminous cross for about a minute and then looking away in an oblique direction against a white background to see the after-image which will be tilted. It can also be demonstrated using a large ball as a model marked with a cross and twirling it between one’s fingers in an oblique axis. Remarkably despite this, one’s perception of the environment remains upright in oblique directions of gaze because the brain erects the mental image. Imagine how disconcerting life would be if the brain were not to do this! In the light of the above-mentioned recent discovery of the rectus muscle fibroelastic pulleys, it seems that Donder’s torsion of the globe in oblique positions of gaze is a passive mechanical result of their presence rather than an action determined by the brain.
Conclusions
It is evident from this discussion that to orchestrate, modulate and coordinate the innervation of our twelve extraocular muscles is a process of immense complexity in the brain. Add to this the speed with which a human eye can rotate (up to 700°/second), its smoothness of movement and the accuracy of gaze redirection, all combine to make the ocular motility system one of truly phenomenal performance. Having a second eye to complement and to be coordinated with the other multiplies the complexity. When the two eyes are moved in unison (termed a version or a conjugate movement) this requires equal innervation to the muscles producing the movement in both eyes (Hering’s Law). With horizontal movements different muscles in each eye contract or relax, e.g. for looking to the left the LR of the left eye and the MR of the right contract together; such paired muscles are termed contralateral synergists or yoke muscles. Despite the intricacies of the computations required, from the conscious decision to look elsewhere or the reflex response to some stimulus (whether visual, auditory, vestibular, tactile, etc), to the synthesis of the command to the ocular motor nuclei in the brainstem, all is accomplished effortlessly in a fraction of a second.
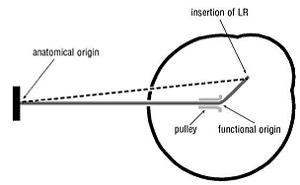
Figure 6. Diagram showing the mechanical effect of the fibroelastic pulley on the action of the LR muscle with the eye elevated. (The dashed line shows the course of the LR in the absence of a pulley.)
The astonishing degree of coordination that our twelve extraocular muscles require and the pulley mechanics of the extraocular musculature all bear overwhelming testimony to meticulous design. Only gross prejudice insists on labelling this as ‘designoid’ (apparent design, as coined by Richard Dawkins). It hardly needs to be said that the muscles without such a highly organised, coherent and sophisticated neural control system would be virtually useless.17 To quote the words of a foremost authority on human ocular motility, Marshall Parks, speaking of the extraocular muscles:
‘The varied combinations of their simultaneous contractions and relaxations offer a myriad of different rotation axes about which the eyes may simultaneously move, a feature made possible by the mechanics created by their various origins and insertions in relation to the rotation center of the globe. The full potential this extraordinary motility system presents would demand a complex innervating system, which it most assuredly possesses.’3
This again raises the question, Where does all the vast amount of genetic information (data) needed to construct such a system come from? Several decades of experiments have shown conclusively that mutations18 never generate new encoded coherent information. In some cases mutations express latent genetic information already present in the genome (including so-called ‘cryptic genes’) which may enable a population to adapt to a changed or hostile environment; otherwise they always represent corruption or loss of information.19 Natural selection, likewise, does not add new genetic information but tends to deplete the gene pool of a population which thereby becomes less adaptable.20 Dawkins believes that not only information but intelligence simply ‘arose’ spontaneously and comparatively recently in his supposed history of the universe.21 By inference, he believes the same of encoded information also, despite the findings of information science22, to say nothing of common sense. What faith indeed!
Acknowledgments
I wish to thank the reviewers together with Dr Michael Siatkowski, Lois Parkes and Robert Higginson for their comments and suggestions on drafts of this paper.
Glossary of terms
Squint or strabismus — failure of the two visual axes (lines of sight) to be directed simultaneously toward a single object of regard.
Corresponding points — pairs of points—one in each retina—which, when stimulated simultaneously by the same image, give rise to a single mental image.
Fusion (sensory) — the ability to perceive two similar images—one in each eye—as one.
Stereopsis — the ability to perceive depth by the fusion of slightly disparate images.
Duction — rotation of the globe; prefixes specify the direction of rotation: ab- means turning out; ad- means in; supra- means elevation; infra- means depression.
Torsion — rolling or rotation of the globe about the anteroposterior (visual) axis; by convention intorsion means torsion that causes the 12 o’clock radius of the cornea to rotate towards the nose and extorsion the opposite.
Primary Position — the term used for the position of the eye when looking directly ahead with the head held erect. Secondary positions are those which are directly up, down, in or out while any oblique position is termed tertiary.
Visual axis — the line of sight, passing through the fovea of the retina
Medial — nearer the midline of the body
Lateral — further from the midline of the body
Origin of a muscle — the less movable of the two points of attachment of a muscle.
Insertion of a muscle — the more movable of the two points of attachment of a muscle.
Listing’s plane — the equatorial plane of the globe bisecting the latter into anterior and posterior halves.
Version — rotation of both eyes in unison; prefixes specify the direction of version: dextro- meaning to the right; laevo- meaning to the left etc.
References
- Crawford, M.J.L., Harwerth, R.S., Chino, Y.M. and Smith, E.L., Binocularity in prism-reared monkeys, Eye 10:161–166, 1996. Return to text.
- Tyler, C.W. and Scott, A.B., Physiologic basis of fusion and diplopia; in: Tasman W. and Jaeger E.A. (Eds), Foundations of Clinical Opthalmology on CD-ROM, Lippincott-Raven Publishers, Inc., New York, vol. 2, ch. 24, 1998. Return to text.
- Parks, M.M., Extraocular muscles; in: Tasman W. and Jaeger E.A. (Eds), Clinical Ophthalmology on CD-ROM, Lippincott-Raven Publishers, Inc., New York vol. 1, ch. 1, 1998. Return to text.
- Wybar, K., Ocular Motility & Strabismus; in: Duke-Elder, S., (Ed.), System of Ophthalmology, Henry Kimpton, London, vol. VI, pp 96–110. 1976. Return to text.
- Consistent with this is the fact that they differ histologically, physiologically and pharmacologically from all other human striated muscle tissue, and have a lower innervation ratio; Ref. 8. Return to text.
- When light falls on a retinal photoreceptor the photopigment it contains is bleached to a varying degree depending on the amount of light. A sustained level of illumination reduces the receptor’s sensitivity to light while, conversely, reducing the level of exposure to light will increase the receptor’s sensitivity. The change in sensitivity of a receptor to light with a change of light exposure is called adaptation—as occurs with our visual adaptation to light and dark surroundings. If an image is stabilised on the retina with a special optical device attached to the eye so that the image is prevented from moving across the retina when the eye is moved, it is found that for the subject the image fades and disappears after several seconds. Thus the physiological microtremor of our eyes (too fine to be seen by the naked eye of an observer) when looking ‘steadily’ or intently at an object, prevents adaptation of the photoreceptors to an image. Return to text.
- Ref. 4, p. 97. Return to text.
- Eggers, H., Functional anatomy of the extraocular muscles; in: Tasman and Jaeger, Ref. 2, vol 1, ch 31. 1998. Return to text.
- Averbuch-Heller, L., Leigh, R.J., Eye Movements; in: Tasman and Jaeger, Ref. 2, vol. 1, ch. 38. Return to text.
- Of all the extraocular muscles the anatomy of the SO muscle is peculiar in that it has what is effectively a cartilagenous pulley. The muscle comprises a) a direct part, 40 mm in length, which is mostly the muscle’s belly from its origin to the trochlea, and b) the reflected part, 20 mm in length, which is entirely tendinous from the trochlea to its insertion. Thus the SO has a longer contractile belly than the IO and yet, because of the trochlea, its direction of pull on the globe is similar to that of the IO. The SO’s longer belly puts it on a par with the inferior rectus (IR) with which it acts synergistically for depression (infraduction). The two most important directions of gaze in everyday life are looking directly ahead and downwards. And so the design of the SO muscle appears to be a refinement to match its power for depression with that of the IR. This would seem to be confirmed by the fact that the SO in lower vertebrates has no trochlea and is replaced by a muscle corresponding exactly with the IO. See Ref. 4, vol. II, pp 423–425, 1961. Return to text.
- Ref. 4. p. 114. Return to text.
- Mein, J., Harcourt, B., Diagnosis and Management of Ocular Motility Disorders, Blackwell Scientific Publications, Oxford, p. 167, 1986. Return to text.
- Demer, J.L., Miller, J.M., Poukens, V., et al., Evidence for fibromuscular pulleys of the recti extraocular muscles, Invest Ophthalmol Vis Sci 36:1125, 1995. Return to text.
- Ettl, A., Kramer, J., Daxer, A., and Koornneef, L., High-resolution magnetic resonance imaging of the normal extraocular musculature, Eye 11:793–797, 1997. Return to text.
- Goldstein, H.P., Scott, A.B., Nelson, L.B., Ocular Motility; in: Tasman and Jaeger, Ref. 2, vol. 2, ch. 23. Return to text.
- Ref. 4, p. 103. Return to text.
- Like striated muscle elsewhere, the extraocular muscles atrophy when denervated. Return to text.
- A mutation is any hereditable change in a gene, i.e. a change in the sequence of base pairs in the chromosomal molecule. Return to text.
- Spetner, L.M., Not by Chance, The Judaica Press, Inc., New York, chs. 5 and 7, 1998. Return to text.
- Wieland, C., Diseases on the Ark, CEN Tech. J. 8(1):16–18, 1994. Return to text.
- Dawkins, R., A transcript of an interview with Sheena McDonald of UK TV Channel 4, 1994, www.infidels.org/library/modern/richard_dawkins/. Return to text.
- Wilder-Smith, A.E., The Creation of Life, TWFT Publishers, Costa Mesa, p.110, 1988. Return to text.
Peter W. V. Gurney qualified in medicine at the University of Bristol, England in 1960. He spent nearly six years as a medical missionary working amongst Muslims in Pakistan, Aden, Ethiopia and Eritrea before returning to the UK to specialise in ophthalmology and completed his training at Moorfields Eye Hospital, London. He is a fellow of the Royal Colleges of Surgeons and of Ophthalmologists, and has practised as a consultant ophthalmologist in the West Midlands since 1980, retiring from full-time service in 1998. Return to top.
Readers’ comments
Comments are automatically closed 14 days after publication.