

Journal of Creation 15(2):55–58, January 1997
Browse our latest digital issue Subscribe
Supplementary information for “The weasel returns: Truman replies to Curtis”
Professor Dawkins describes his computer programs, written in Basic and later in Pascal, using words such as ‘mutation’, ‘generation’, ‘selection’, and so on. But he does not inform us just what the sentences actually represent. They might represent genes, proteins, operons or genomes, although from the context and from other publications an expressed gene is most likely.
The parameters and programming details are not based in the remotest on any biological data, or on considerations such as base-pair mutational probability, codon redundancy, population genetics, effect of neutral and destructive mutations, reproductive selectivity coefficients, etc.
A simpler algorithm, which reproduces the guaranteed convergence behaviour, clarifies what Dawkins’ algorithm actually shows: that change is only possible towards a pre-selected goal. Once a letter falls into place, Dawkin’s program ensures it won’t mutate away. This is shown in the two following examples:
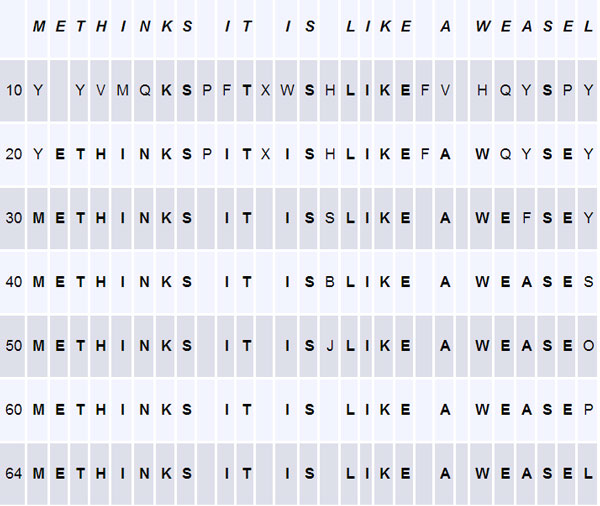

Truman’s data for Dawkins’ weasel
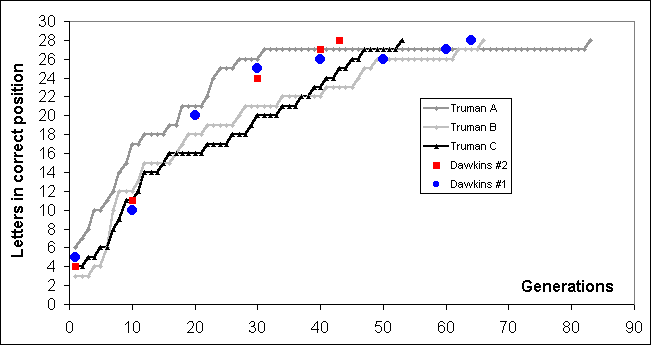
Figure 1. (Click figure to enlarge)
Convergence behaviour from Truman’s program straddles that reported by Dawkins (some runs were selected out of 40 generated from Truman’s program).
The data for the three curves in Figure 1 labelled ‘Truman A’, ‘B’, and ‘C’ is in the spreadsheet ‘ImprovementRate’.
 Figure 2. (Click figure to enlarge) Data generated by Dawkins’ program and approximate average of 10,000 runs from Truman’s. On average Truman’s curves lie further to the right (they converge a little more slowly). |
The data for Figure 2 has not been supplied as a table. This data is complex and rather long. The raw basis is found in the spreadsheet ‘Original summary 10,000 sorted’ (0.5 MB file). At the bottom of the second column an ‘Average=’ function has been added. Notice that the grand average for 10,000 runs is 102 generations for convergence to the target sentence.
The data plotted in Figure 2 (i.e. average number of letters lined up after each generation) is found in the spreadsheet ‘Dawkins vs Truman’. Approximate weighted number of successful letters [as mentioned, using the raw data in the last sheet (Original summary 10,000 sorted)] per generation was used. Notice from the first column that indeed the average number of generations needed for all 28 letters to be lined up is 102.
Readers’ comments
Comments are automatically closed 14 days after publication.