
Das mysteriöse außerirdische Tablet
Ein Blick in das verblüffende, vielschichtige Informationssystem der DNS

Laut Bill Gates, einem der Gründer der Firma Microsoft, „ist die DNS wie ein Computerprogramm, aber viel, viel höher entwickelt als jede Software, die jemals geschaffen wurde.“1 Gates bezieht sich hier auf das „Genom“ – die in der DNS kodierten Anweisungen, die zur Steuerung der Embryonalentwicklung (beim Menschen zur Steuerung des Wachstums eines Babys ausgehend von einer befruchteten Eizelle) und für die tägliche Arbeit der biologischen Zellen benötigt werden.
Um dem Leser einen kleinen Einblick in die Raffinesse der DNS zu geben, erzähle ich eine imaginäre Geschichte über den Fund eines elektronischen Tablets in einem verlassenen außerirdischen Raumschiff.2 Auf diesem fand man eine ganze Bibliothek mit elektronischen Dokumenten und Büchern.
Der Fund sorgte für große Aufregung und die besten Linguisten der Welt arbeiteten zusammen, um die seltsamen Symbole in den Büchern zu entziffern. Ein Dokument enthielt Diagramme des Schiffsgrundrisses und des Maschinenraums, wobei viele Teile beschriftet waren. Dies lieferte die entscheidenden Anhaltspunkte, um die fremde Sprache zu entschlüsseln.
Je mehr die Bücher studiert wurden, desto verblüffender wurde es für die Linguisten. In einer Besprechung berichtete ein Professor, dass die Sätze wie im Hebräischen von rechts nach links gelesen werden müssten. Ein anderer war anderer Meinung und sagte, dass sie wie im Englischen von links nach rechts gelesen werden sollten. Weitere Untersuchungen ergaben, dass beide Recht hatten. Ein anderer aus dem Team hatte etwas studiert, das wie eine Bedienungsanleitung für die Wartung des Raumschiffantriebssystems aussah. Er entdeckte, dass dieselbe Reihe von Zeichen (oder Symbolen) typischerweise von links nach rechts gelesen werden musste, um eine Anweisung zu erhalten, und dann von rechts nach links, um eine andere Anweisung zu erhalten. Das heißt, jede Zeichenkette schien zwei Bedeutungen zu haben!

Einige Wochen später kam ein anderer Professor, ein Experte für Kryptologie, mit vor Aufregung gerötetem Gesicht ins Besprechungszimmer gestürmt. Er hatte entdeckt, dass einige Teile der gleichen Betriebsanleitung in verschiedenen Sprachen gelesen werden konnten. Später erklärte er einem Zeitungsreporter, dass es ein bisschen so sei, als hätte man ein Buch, in dem man zuerst auf Englisch liest, um die erste Hälfte der Geschichte zu erfahren, und dann wieder auf der ersten Seite anfängt und die gleichen Worte auf Französisch liest, um die zweite Hälfte der Geschichte zu erfahren!
In einer dieser Sprachen hatten außerdem alle Wörter nur drei Buchstaben. Wenn man nun mit verschiedenen Buchstaben begann, erhielt man völlig unterschiedliche Sätze mit verschiedenen Bedeutungen! In einem Abschnitt lautete der Grundtext zum Beispiel wie folgt:3

Wenn man die Drei-Buchstaben-Wörter an Position 1 begann (Diagramm oben), stellte sich heraus, dass die Aussage des Satzes eine Vorgabe für ein Kraftstoffgemisch war. Begann man bei Position 2, handelte es sich um eine Anweisung zum Umgang mit einer möglicherweise schädlichen Motorvibration. Begann man bei Position 3, wurde davor gewarnt, die Motoren zu schnell laufen zu lassen, bevor sie ihre optimale Betriebstemperatur erreicht haben; las man die so erhaltene Zeichenfolge rückwärts, erhielt man Informationen, die für einen Neustart des Motorcontrollers benötigt werden.
Wie der Projektleiter bemerkte, gab es ein erstaunliches Maß an „Datenkompression“, bei der eine Menge an Informationen in eine kurze Zeichenkette gepackt war. Ein spezieller Zeichensatz schien sogar bis zu 12 verschiedene Anweisungen zu enthalten, je nachdem, wie er gelesen wurde!
Sechs Monate später gab es eine weitere bemerkenswerte Entdeckung. Als eine Forscherin einen ruhigen Ort zum Arbeiten suchte, nahm sie das Tablet mit in einen Raum, der offenbar die Bordküche des Raumschiffs war. Als sie dann ein Dokument öffnete, bemerkte sie, dass einige der Zeichen „ausgegraut“ und kaum sichtbar waren.
Indem sie nur die dunklen Zeichen las, fand sie ein Rezept für eine Mahlzeit auf der Mittagskarte. Das Dokument schien „kontextabhängig“ zu sein, was bedeutet, dass es sich selbst veränderte, um die Informationen bereitzustellen, die für die jeweilige Ausführung bestimmter Aufgaben an einem bestimmten Ort benötigt wurden. Dies wurde bestätigt, als die Forscherin das Tablet in einen anderen Raum mitnahm, der offenbar die Navigationszentrale war. Sofort änderte sich der Text so, dass verschiedene Zeichen ausgegraut wurden. Der daraus resultierende lesbare Text entpuppte sich später als Teil einer Prozedur zum Berechnen eines Kurses durch ein fernes Sonnensystem.
Informationssysteme in biologischen Zellen
Unsere Geschichte mag dem Leser phantastisch erscheinen, aber es gibt Parallelen in der realen Welt, denn das menschliche Genom ist ganz analog aufgebaut.4 Die DNS kann vorwärts und rückwärts gelesen werden, und verschiedene Anweisungen können sich oft überschneiden, sogar in umgekehrter Reihenfolge. Wie bei der fremden Sprache werden an vielen Stellen im Genom verschiedene „Sätze“ gebildet, indem man mit unterschiedlichen Buchstaben beginnt. Und so wie sich der Text, den das Tablet der Außerirdischen anzeigte, automatisch änderte, je nachdem, in welchem Raum es sich befand, werden auch die Gene (DNS-Anweisungen) automatisch ein- oder ausgeschaltet, was dazu führt, dass sich Pflanzen und Tiere verändern oder anders funktionieren und sich an unterschiedliche Umgebungen anpassen können.
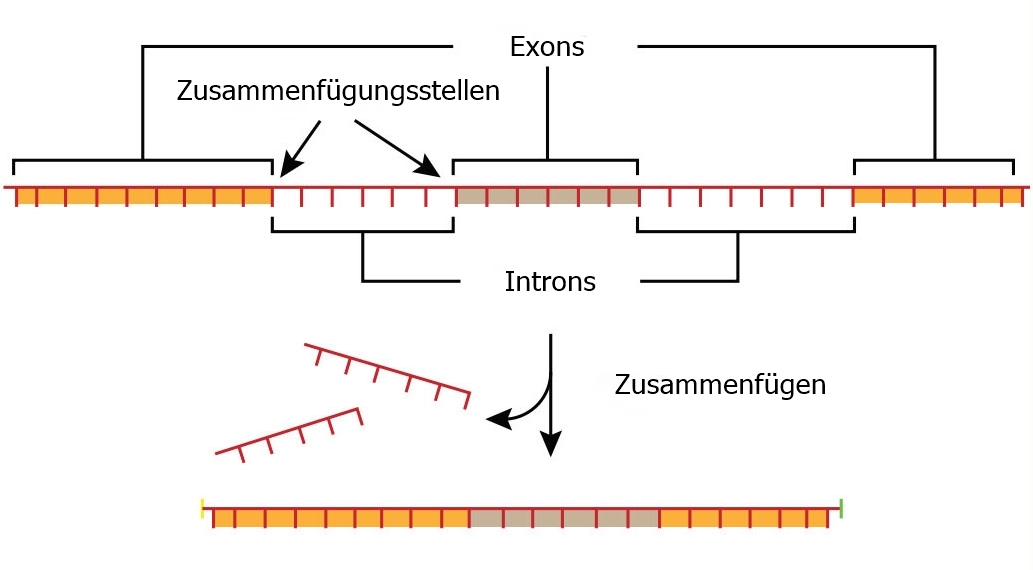
Mehr noch, menschliche Gene bestehen aus Gruppen von DNS-„Buchstaben“, die in einzelne Abschnitte unterteilt sind, die als „Introns“ und „Exons“ bekannt sind. Nachdem die DNS kopiert wurde, müssen die Introns entfernt und die verbleibenden Exons zusammengefügt werden (siehe Abb. 1). Verschiedene Exons werden auf unterschiedliche Weise kombiniert, um viele verschiedene Anweisungen zu erzeugen. Diese wiederum werden verwendet, um verschiedene Proteine zu verschiedenen Zeiten zu produzieren, und die produzierten Proteine variieren von einem Zelltyp zum anderen. Tatsächlich verfügt das menschliche Genom über ein massives „Zerschneidungs- und Zusammenfügungssystem“, das die DNS „zerschneidet und wieder zusammenfügt“ und Exons auf sehr komplexe Weise austauscht.5 Ein einzelnes Exon kann in vielen verschiedenen Genen enthalten sein, von denen einige für Proteine kodieren (d. h. die Form von Proteinen spezifizieren), die wenig Ähnlichkeit miteinander haben. Bei Fruchtfliegen (Drosophila) kann ein und dasselbe „Gen“ Tausende von verschiedenen Proteinen spezifizieren.6
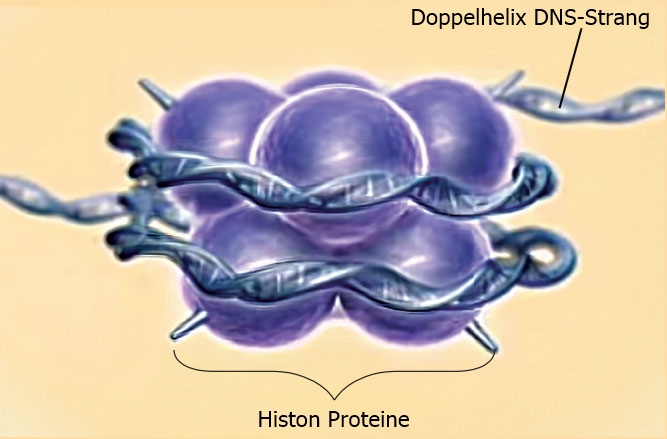
Außerdem kann ein und dieselbe Buchstabengruppe unterschiedliche Bedeutungen haben, je nachdem, welche „Sprache“ zum Lesen verwendet wird. Ein Abschnitt der DNS kann gleichzeitig für die Form eines Proteins, eine Intron-Exon-Zusammenfügungsstelle (Abb. 1) und eine Histon-Bindungsstelle (siehe Abb. 2) kodieren (d. h. die Anweisungen dafür liefern). All dies erfordert unterschiedliche biologische Nanomaschinen, um die Informationen zu „lesen“ und darauf zu reagieren.
Unsere Alien-Sprach-Analogie ist nur ein schwacher Abglanz der erstaunlichen Komplexität der Sprache der DNS, und das Informationssystem in den Zellen ist tatsächlich noch weitaus ausgeklügelter. Zum Beispiel ist die DNS nicht das einzige Molekül, das Informationen in der Zelle trägt. Andere Moleküle, wie langkettige Zucker,7 werden ebenfalls verwendet, um Proteine zu modifizieren. Auch die Muster der Zellmembran und sogar die elektrischen Felder, die von Membranmolekülen erzeugt werden, tragen wichtige Informationen. All dies steuert, wie Embryos wachsen und wie der erwachsene Körper funktioniert.
Vertreter der Evolutionstheorie waren noch nie in der Lage, Prozesse in der Natur aufzuzeigen, die auch nur im Entferntesten ein Informationssystem mit einem solch hohen Grad an Komplexität und Raffinesse erzeugen könnten. Vielmehr nehmen sie einfach im Glauben an, dass solche Prozesse existieren. Insbesondere ist es für Darwinisten sehr schwierig, DNS-Sequenzen zu erklären, die auf viele verschiedene Arten funktionieren. Selbst wenn eine zufällige Mutation zu einer Verbesserung einer speziell ausgelesenen Sequenz führen sollte, würde sich der Informationsgehalt fast ausnahmslos verringern, wenn man dieselbe Sequenz auf eine andere Art und Weise ausliest.
Wenn wir die Schönheit und Komplexität der biologischen Welt betrachten, sollten wir daher mit Recht wie König David die folgenden Worte aus Psalm 139,14 an Gott richten: „Ich danke dir dafür, dass ich erstaunlich und wunderbar gemacht bin; wunderbar sind deine Werke, und meine Seele erkennt das wohl!“
Literaturangaben und Anmerkungen
- Gates, B., The Road Ahead, Penguin Group, New York, p. 188, 1995. Zurück zum Text.
- CMI lehnt natürlich die Idee von Außerirdischen auf anderen Planeten ab—siehe unsere Dokumentation Alien Intrusion: Unmasking the Deception. Zurück zum Text.
- Die Symbole in der verwendeten Illustration sind eine altpersische Keilschrift, hier in zufälliger Anordnung. Zurück zum Text.
- Sanford, J., Genetic Entropy and the Mystery of the Genome, Ivan Press, New York, pp. 131–133, 2005. Zurück zum Text.
- Carter, R., Splicing and dicing the human genome; creation.com/splicing, 29 Jun 2010. Zurück zum Text.
- Zinn, K., Dscam and neuronal uniqueness, Cell 129(3):455–456, 4 May 2007; cell.com. Zurück zum Text.
- Während DNS und RNS Sequenzen eindimensional sind, sind Zuckermoleküle dreidimensional und können noch wesentlich mehr Information speichern. Siehe Wells, J., Membrane patterns carry ontogenetic information that is specified independently of DNA, BIO-Complexity 2:1–28, 2014; bio-complexity.org. Siehe auch, ID inquiry: Jonathan Wells on codes in biology, Interview, Discovery Institute, 2015; discovery.org. Zurück zum Text.

Readers’ comments
Comments are automatically closed 14 days after publication.